|
日历归档 |
|
|
| << < 2025 - 05 > >> | | Su | Mo | Tu | We | Th | Fr | Sa | | | | | | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
|
|
|
|
|
|
About Me |
|
|
|
|
ZhangSichu |
|
|
Male |
|
|
32 |
|
|
ZhangSichu@gmail.com |
|
|
ZhangSichu@hotmail.com |
|
|
ZhangSichu.com |
|
|
weibo.com/zhangsichu |
|
|
|
|
|
|
个人推荐 |
|
|
|
|
|
|
|
|
|
分类归档 |
|
|
|
|
|
|
|
|
My Friends |
|
|
|
|
|
|
|
Yield Return 中的递归迭代
|
在看关于 yield return的介绍文章中,发现 yield可以非常方便的实现二叉树的遍历。
原文地址:http://www.microsoft.com/china/msdn/library/langtool/vcsharp/CreElegCodAnymMeth.mspx?mfr=true
下面两个章节是摘引自原文:
----------------------------------------------------------------------------------------------------
迭代程序实现
编译器生成的嵌套类维持迭代状态。当在 foreach 循环中(或在直接迭代代码中)首次调用迭代程序时,编译器为 GetEnumerator 生成的代码将创建一个带有 reset 状态的新的迭代程序对象(嵌套类的一个实例)。在 foreach 每次循环调用迭代程序的 MoveNext 方法时,它都从前一次 yield return 语句停止的地方开始执行。只要 foreach 循环执行,迭代程序就会维持它的状态。然而,迭代程序对象(以及它的状态)在多个 foreach 循环之间并不保持一致。因此,再次调用 foreach 是安全的,因为您将使新的迭代程序对象开始新的迭代。这就是为什么 IEnumerable <ItemType> 没有定义 Reset 方法的原因。
但是嵌套迭代程序类是如何实现的呢?并且如何管理它的状态呢?编译器将一个标准方法转换成一个可以被多次调用的方法,此方法使用一个简单的状态机在前一个 yield return 语句之后恢复执行。您需要做的只是使用 yield return 语句指示编译器产生什么以及何时产生。编译器具有足够的智能,它甚至能够将多个 yield return 语句按照它们出现的顺序连接起来:
public class CityCollection : IEnumerable<string>
{
public IEnumerator<string> GetEnumerator()
{
yield return "New York";
yield return "Paris";
yield return "London";
}
}
|
让我们看一看在下面几行代码中显示的该类的 GetEnumerator 方法:
public class MyCollection : IEnumerable<string>
{
public IEnumerator<string> GetEnumerator()
{
//Some iteration code that uses yield return
}
}
|
当编译器遇到这种带有 yield return 语句的类成员时,它会插入一个名为 GetEnumerator$<random unique number>__IEnumeratorImpl 的嵌套类的定义,如图 5 中 C# 伪代码所示。(记住,本文所讨论的所有特征 ― 编译器生成的类和字段的名称 ― 是会改变的,在某些情况下甚至会发生彻底的变化。您不应该试图使用反射来获得这些实现细节并期望得到一致的结果。)嵌套类实现了从类成员返回的相同 IEnumerable 接口。编译器使用一个实例化的嵌套类型来代替类成员中的代码,将一个指向集合的引用赋给嵌套类的 <this> 成员变量,类似于图 2 中所示的手动实现。实际上,该嵌套类是一个提供了 IEnumerator 的实现的类。
返回页首
递归迭代
当在像二叉树或其他任何包含相互连接的节点的复杂图形这样的数据结构上进行递归迭代时,迭代程序才真正显示出了它的优势。通过递归迭代手动实现一个迭代程序是相当困难的,但是如果使用 C# 迭代程序,这将变得很容易。请考虑图 6 中的二叉树。这个二叉树的完整实现是本文所提供的源代码的一部分。这个二叉树在节点中存储了一些项。每个节点均拥有一个一般类型 T(名为Item)的值。每个节点均含有指向左边节点的引用和指向右边节点的引用。比 Item 小的值存储在左边的子树中,比 Item 大的值存储在右边的子树中。这个树还提供了 Add 方法,通过使用参数限定符添加一组开放式的 T 类型的值:
public void Add(params T[] items);
这棵树提供了一个 IEnumerable <T> 类型的名为 InOrder 的公共属性。InOrder 调用递归的私有帮助器方法 ScanInOrder,把树的根节点传递给 ScanInOrder。ScanInOrder 定义如下:
IEnumerable<T> ScanInOrder(Node<T> root);
它返回 IEnumerable <T> 类型的迭代程序的实现,此实现按顺序遍历二叉树。对于 ScanInOrder 需要注意的一件事情是,它通过递归遍历这个二叉树的方式,即使用 foreach 循环来访问从递归调用返回的 IEnumerable <T>。在顺序 (in-order) 迭代中,每个节点都首先遍历它左边的子树,接着遍历该节点本身的值,然后遍历右边的子树。对于这种情况,需要三个 yield return 语句。为了遍历左边的子树,ScanInOrder 在递归调用(它以参数的形式传递左边的节点)返回的 IEnumerable <T>上使用 foreach 循环。一旦 foreach 循环返回,就已经遍历并产生了左边子树的所有节点。然后,ScanInOrder 产生作为迭代的根传递给其节点的值,并在 foreach 循环中执行另一个递归调用,这次是在右边的子树上。通过使用属性 InOrder,可以编写下面的 foreach 循环来遍历整个树:
BinaryTree<int> tree = new BinaryTree<int>();
tree.Add(4,6,2,7,5,3,1);
foreach(int num in tree.InOrder)
{
Trace.WriteLine(num);
}
// Traces 1,2,3,4,5,6,7
|
可以通过添加其他的属性用相似的方式实现前序 (pre-order) 和后序 (post-order) 迭代。虽然以递归方式使用迭代程序的能力显然是一个强大的功能,但是在使用时应该保持谨慎,因为可能会出现严重的性能问题。每次调用 ScanInOrder 都需要实例化编译器生成的迭代程序,因此,递归遍历一个很深的树可能会导致在幕后生成大量的对象。在对称二叉树中,大约有 n 个迭代程序实例,其中 n 为树中节点的数目。在任一特定的时刻,这些对象中大约有 log(n) 个是活的。在具有适当大小的树中,许多这样的对象会使树通过 0 代 (Generation 0) 垃圾回收。也就是说,通过使用栈或队列维护一列将要被检查的节点,迭代程序仍然能够方便地遍历递归数据结构(例如树)。
----------------------------------------------------------------------------------------------------
其中链接给的实例代码。
----------------------------------------------------------------------------------------------------
http://www.microsoft.com/china/msdn/library/langtool/vcsharp/art/C20fig06.htm
Figure 6 Implementing a Recursive Iterator
class Node<T>
{
public Node<T> LeftNode;
public Node<T> RightNode;
public T Item;
}
public class BinaryTree<T>
{
Node<T> m_Root;
public void Add(params T[] items)
{
foreach(T item in items)
Add(item);
}
public void Add(T item)
{...}
public IEnumerable<T> InOrder
{
get
{
return ScanInOrder(m_Root);
}
}
IEnumerable<T> ScanInOrder(Node<T> root)
{
if(root.LeftNode != null)
{
foreach(T item in ScanInOrder(root.LeftNode))
{
yield return item;
}
}
yield return root.Item;
if(root.RightNode != null)
{
foreach(T item in ScanInOrder(root.RightNode))
{
yield return item;
}
}
}
}
|
文章中讲到的两个地方,我读了感觉没有明白:
1. 在 foreach 每次循环调用迭代程序的 MoveNext 方法时,它都从前一次 yield return 语句停止的地方开始执行。
2. 对于这种情况,需要三个 yield return 语句。为了遍历左边的子树,ScanInOrder 在递归调用(它以参数的形式传递左边的节点)返回的 IEnumerable <T>上使用 foreach 循环。一旦 foreach 循环返回,就已经遍历并产生了左边子树的所有节点。然后,ScanInOrder 产生作为迭代的根传递给其节点的值,并在 foreach 循环中执行另一个递归调用,这次是在右边的子树上。
实例代码中没有给出Add方法的实际实现。也就没有办法对代码进行跟踪和调试,仔细观察代码的运行过程。体会这两点的含义。
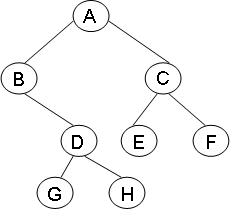
下面的代码实现了Add方法的功能,使整个程序可以Debug了。测试代码填充的BinaryTree如下图:
public class ConsoleTest
{
public static void Main(string[] args)
{
// Test 1.
// yield break.
// yield return.
#region Test 1
ListClass list = new ListClass();
foreach (string i in list)
{
Console.Write(i);
}
#endregion
// Test 2 yield Iterator.
#region Test 2
Node<string>[] nodes = new Node<string>[8];
nodes[0] = new Node<string>("A");
nodes[1] = new Node<string>("B");
nodes[2] = new Node<string>("C");
nodes[3] = new Node<string>("D");
nodes[4] = new Node<string>("E");
nodes[5] = new Node<string>("F");
nodes[6] = new Node<string>("G");
nodes[7] = new Node<string>("H");
nodes[0].LeftNode = nodes[1];
nodes[0].RightNode = nodes[2];
nodes[1].RightNode = nodes[3];
nodes[2].LeftNode = nodes[4];
nodes[2].RightNode = nodes[5];
nodes[3].LeftNode = nodes[6];
nodes[3].RightNode = nodes[7];
BinaryTree<string> tree = new BinaryTree<string>(nodes[0]);
BinaryTreeScanInOrder<string> inOrder = new BinaryTreeScanInOrder<string>(tree);
foreach (string item in inOrder.InOrder)
{
Trace.WriteLine(item);
}
#endregion
}
}
#region For Test 1
public class ListClass : IEnumerable
{
public IEnumerator GetEnumerator()
{
yield return "With an iterator, ";
yield return "more than one ";
yield break;
yield return "value can be returned";
yield return ".";
}
}
#endregion
#region For Test 2
public class Node<T>
{
public Node<T> LeftNode;
public Node<T> RightNode;
public T Item;
public Node(T item)
{
this.Item = item;
}
}
public class BinaryTree<T>
{
public Node<T> Root;
public BinaryTree(Node<T> root)
{
this.Root = root;
}
}
public class BinaryTreeScanInOrder<T>
{
private BinaryTree<T> _binaryTree;
public BinaryTreeScanInOrder(BinaryTree<T> binaryTree)
{
this._binaryTree = binaryTree;
}
public IEnumerable<T> InOrder
{
get
{
return ScanInOrder(_binaryTree.Root);
}
}
public IEnumerable<T> ScanInOrder(Node<T> root)
{
if (root.LeftNode != null)
{
foreach (T item in ScanInOrder(root.LeftNode))
{
yield return item;
}
}
yield return root.Item;
if (root.RightNode != null)
{
foreach (T item in ScanInOrder(root.RightNode))
{
yield return item;
}
}
}
}
#endregion
|
 File: 本文实例程序 File: 本文实例程序
|
|
|
#re:Yield Return 中的递归迭代 4/11/2008 4:31:18 PM aeron
|
|
|
|
|
|
|
|




 2025年5月18日 星期日
2025年5月18日 星期日